Relocation to the data center: the case of IT infrastructure migration in Frankfurt
Contents
- 1 Under the mask of reliability: critical situation as a reason to move to a new data center
- 2 Beginning of cooperation: negotiations
- 3 Project Features
- 4 How to organize relocation to a new data center without losses: a step-by-step relocation plan
- 4.1 Stage One: preparing for relocation on the side of the old data center
- 4.2 Stage Two: Preparing for migration in our data center
- 4.3 Stage Three: relocating to the new data center
- 4.4 Migration between data centers without a backup plan: what was difficult in the project
- 4.5 The project’s organization
- 5 Duration and participants of each stage of the project
- 6 Continued cooperation
- 7 How IT infrastructure grew in the new data center
- 8 Reliable service is a guarantee of IT infrastructure uptime
- 9 Secrets of client loyalty: why they change service providers
- 10 Exclusive service from CloudKleyer: our benefits
- 11 Migration budget: how to relocate without excessive expenses
- 12 Stable tariffs for the entire term of the contract
- 13 The concept of social responsibility
Relocating IT infrastructure to a new data center is important step for the business. There must be very good reasons to decide to migrate. The client we are describing in this case study had plenty of reasons to move the infrastructure: starting with issues in communicating with the service provider’s technical support and up to high risks that might have led the client to significant financial losses.
The details of this story will be revealed gradually. You will learn the dangers of poor communication with technical support, why the client had to urgently search for a new data center (DC) and decided to relocate without a backup plan. Also we will tell you in detail how the migration proceeded and how much the company saves annually on renting the racks in the new data center.
Under the mask of reliability: critical situation as a reason to move to a new data center
The client’s IT infrastructure was hosted in the big and well-known data center in Germany. Such choice usually promises stability and reliability, as well as high level of service. Clients of this data center expect that a chance of force majeure and downtime is minimal, the hardware will be maintained in operating condition, and technical support service will quickly solve any emerging issues (both urgent and ongoing). No one assumes that the nuances of service, provided by this data center, can put a business in critical situation.
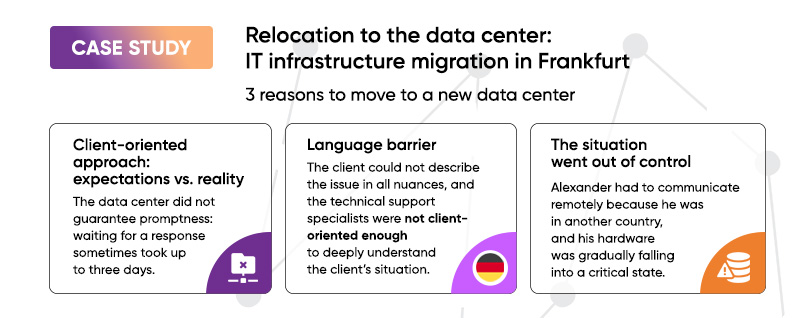
Client-oriented approach: expectations vs. reality
The head of IT department of one famous e-store (hereinafter referred to as Alexander) could not have imagined what he was risking when he ordered a space rental in one of Frankfurt’s most reputable data centers. However, the service provider was not properly client-oriented, which ultimately led to serious issues that could have caused significant damage to financial and reputational well-being of the entire e-commerce company.
In the selected data center, a client with one rack was considered as insignificant entity and received attention only at the initial stage of cooperation. In order to contact the technical support department of the data center, the client had to go through a cumbersome sequence of the following actions:
- access the client’s portal, puzzle out sophisticated navigation there, and find the section for contacting technical support specialist;
- create a ticket, describing an issue which occurred in precise technical detail in English language;
- wait for a technical support specialist to respond to the client’s request.
The data center did not guarantee promptness: waiting for a response sometimes took up to three days, which precluded a quick solution. Obviously, such approach is unacceptable and puts the client’s business at risk, especially when it comes to critical situations that require immediate response.
Language barrier
The interface of the ticket system was not only confusing but was in English language, which Alexander did not understand well. The portal did not support other languages. Due to the language barrier, the client could not describe the issue in all the technical nuances, and the technical support specialists were not client-oriented enough to deeply understand the client’s situation from the start.
At first, Alexander had a personal manager with whom he could communicate in his native language, and the data center specialist provided minimal assistance. And, at the same time, all questions of technical nature had to be asked via the ticket system. After the technical support specialist was replaced with English-speaking technician, the situation worsened. The client was completely isolated: he could not clearly explain an issue with the IT infrastructure, and the new technician often misinterpreted requests or answered in such a way that it was not clear for Alexander how to act under such circumstances.
The situation went out of control
Alexander had to communicate remotely: he was in another country and had no opportunity to come to the data center in person. Since the service provider did not monitor the state of the IT infrastructure, did not provide maintenance, and did not help to solve current issues, the client’s hardware was gradually falling into a critical state.
It should be noted that Alexander was fully responsible for the IT infrastructure of the e-store, which had many customers and processed hundreds of orders worth of tens of thousands of euros every day. Alexander was very worried that he could not control the resource management process. Since calls to the helpdesk were not yielding any results, a lot of issues had accumulated with the rented hardware and software, so this could lead to a disaster at any moment and cause both reputational and major financial damage to the business.
When the situation reached a critical point: hard disks started failing one by one, the disk subsystem was damaged, and the technical support service did not provide any help, Alexander’s patience came to an end. He was forced to make the only right decision: to transfer the IT infrastructure to another service provider and relocate it to a new data center.
 "Poor quality and untimely maintenance of IT infrastructure can have disastrous consequences for a business. If data center specialists do not provide the necessary level of control and service, relocating to another provider – is the right way out" – Volodymyr Marchenko
"Poor quality and untimely maintenance of IT infrastructure can have disastrous consequences for a business. If data center specialists do not provide the necessary level of control and service, relocating to another provider – is the right way out" – Volodymyr Marchenko
All that remained to do was to find another, more suitable, service provider.
Criteria for selecting a service provider
When selecting a new service provider and data center, Alexander focused on the following criteria:
- Data center should be located in Frankfurt am Main. It should have a really high level of reliability, SLA from 99%, guaranteed data security and uninterrupted operation of the infrastructure.
- It should provide its clients with the opportunity to quickly contact project managers and technical specialists directly, i.e. without ticket system, via convenient communication channels, and in their native language.
- Its technical support service should be available 24/7/365, respond promptly to requests, and provide feedback online.
- 90% of issues with the client hardware should be resolved by the provider on-site without involving clients and resource owners.
Another aspect that was very important for Alexander was the option to delegate to the service provider both the maintenance of IT infrastructure and all aspects related to the conclusion and maintenance of the service contracts.
While searching for a more suitable data center to migrate to, for Alexander it was necessary to take urgent action to avoid an approaching disaster, the probability of which was increasing every day. He did not trust the technical support service of the current data center for the reasons mentioned above. Knowing about the situation, his partners recommended using CloudKleyer services, as they had a successful experience of cooperation with us. This is how we met Alexander and his company, which turned into a long-term mutually beneficial partnership.
Beginning of cooperation: negotiations
Alexander first contacted us in September . He required immediate professional assistance in replacing his failed hard disks. The first business meeting was very intense and opened up great prospects for our future cooperation.
Alexander told us about the situation in which he found himself due to the failings in service provision by the DC with which he worked previously, outlined his plans for migration and the criteria he used when selecting a new provider. He had a lot of questions related to the future migration. For example, he needed IBM expert who could deal with software issues, and asked us if we could provide such a specialist. Alexander also expressed interest in leasing: the company was planning to lease the hardware from the data center with the possibility of subsequent buy out. In this regard, it was important for him that the new provider could take over the work with service companies, relieving Alexander of the need to interact with them.
For our part, we presented our approach to customer service, offered a suitable option for solving issues, described how the migration is performed, and answered some of the questions that did not require additional technical data. In fact, preparations for the relocation began immediately, because after the initial meeting we have started gathering information, established contact with IBM and started negotiations with the vendor’s representatives.
A week later the second meeting took place, at which we provided all the information Alexander required. He was completely satisfied with the answers, announced his desire to become a CloudKleyer client and to relocate the IT infrastructure of the e-store to our data center. Shortly after the preliminary negotiations, the final decision on cooperation was made and the service agreement with Alexander’s company was signed.
"As always, we showed maximum attention to the interests and needs of the client. This played a key role in the decision to switch to us as a service provider" – Olga Boujanova
Project Features
One of the reasons for the relocation was the critical state of the client’s IT infrastructure. In addition, the owners of the e-store were planning to lease additional hardware and, eventually, to buy it out. At the same time, the company’s current hardware was specific and outdated: some of it had already been taken out of the service by its manufacturer.
With all this in mind, we were faced with a number of challenging tasks. We had to do the following:
- restore operability of the current IT infrastructure and resolve software issues;
- prepare the hardware for the migration and relocate it without long downtimes, which could have a negative impact on the operating business;
- find service companies willing to take on maintenance of unique outdated hardware, negotiate with them and sign service contracts;
- provide the client company with an opportunity to buy out the hardware on favorable terms.
Having concluded a framework agreement with the client, we began to restore their hardware to a workable state. This work had to be done before the relocation took place, so CloudKleyer technical experts visited the “old” data center, where the client’s IT infrastructure was originally located. To stop the destructive processes for critical infrastructure, the first thing they did was to replace hard disks in the RAID array. Then they started to prepare the hardware for relocation. The relocation was scheduled for the beginning of January, the period of lowest customer activity.
When everything was ready, we agreed with Alexander to meet again to approve the relocation plan.
Further on we will talk in detail about all the stages and nuances of this relocation.
How to organize relocation to a new data center without losses: a step-by-step relocation plan
We completely took over the relocation process. Each stage was carefully thought out with just one goal in mind: to relocate the client’s IT infrastructure with minimal losses for the business.
Stage One: preparing for relocation on the side of the old data center
Technical audit of the IT infrastructure
First of all, it was necessary to analyze the state of the IT infrastructure and do inventory. It was highly important to understand how the client’s hardware was connected in the original data center to restore the existing connections at the network level after the relocation. First of all, we asked the client for the list of all their hardware, as well as connection patterns.
The hardware is special, and errors could occur during the relocation. To eliminate this, CloudKleyer’s technical engineers specifically went to the data center where the client rented a rack. There they conducted an audit of all the client’s network resources and checked the status of the servers. The results of this analysis were documented and photographed.
Making a plan
All hardware for the relocation took up six shelves on a single rack. They included the following:
- four large servers;
- one small server;
- three storage units with expansions;
- one router and four switches (two for each – for Fibre Channel and Ethernet).
Having done an audit of the IT infrastructure, we have drawn detailed relocation plan.
Stage Two: Preparing for migration in our data center
At the second stage, we carried out preparatory works in our data center. To ensure that the IT infrastructure in the future will operate smoothly at the new location, CloudKleyer technical experts carried out a thorough preparation of resources for data migration. This is a complex process that demands attention: simply connecting hardware to power grid after its relocation is not enough; you have to establish connections between different components, connect them to the “outside world”: Internet, networks of other providers, etc. Therefore, we had to ensure that the network hardware and communications were ready on our end before we started the relocation.
Stage Three: relocating to the new data center
Since we cannot interrupt the company’s operations for a long period of time, we had to relocate during the quietest period for the business and to do it as quickly as possible. That is why so much attention was paid to the preparatory activities. The date for relocation was set for one of the first nights in January when the IT infrastructure is least loaded, i.e. when the e-store traffic is at its lowest.
After the preparatory work was completed, on the predetermined day we have started the third and most important step – migration. The direct migration of the IT infrastructure lasted a total of 6 hours: from the moment the hardware was shut down in the old data center to its launch in the new one.
The procedure we followed during the relocation
- In the initial data center: we labeled and photographed all hardware, made detailed connection diagram, disconnected servers, packed the hardware for transportation, and loaded it.
- In the new data center: we unloaded, unpacked, rack mounted the hardware, connected, and tested the system.
So, we dismantled the entire existing configuration, carefully relocated the hardware and re-established all connections in a precise sequence in the new data center.
During the relocation, while the technicians were doing their work, the project coordinator was in constant communication with the client, keeping Alexander informed about the progress of the migration in detail.
At CloudKleyer, we know how important every step of this process to you. Let us make your transition to a new data center as comfortable and cost effective as possible. We are always ready to help!
Please contact us to get a free consultation
Migration between data centers without a backup plan: what was difficult in the project
There were no major technical bugs or difficulties – the migration procedure went as planned. The only thing we didn’t expect was that one of the links wouldn’t work. But the technicians solved the issue in a couple of minutes, and everything worked as normal.
Only the psychological state of Alexander can be considered as a difficulty. He was facing migration for the first time and was very worried because he had a heavy burden of responsibility on his shoulders. He was solely responsible for IT infrastructure of a large e-store with a large number of business processes that should not be stopped. A lot of customers, orders, payments acceptance, and shipment of purchases. If the servers would become unavailable after the relocation, the e-store would simply stop working, and the business will start to suffer serious losses, above all, its reputation would suffer. At the same time, there was no backup option – no plan B, which could have saved the situation in the event of force majeure – the client had to trust our team completely.
Understanding Alexander’s anxiety, the project coordinator kept in touch with him, tried to give him moral support and reassure him that everything was going as planned. Nevertheless, after the issues with the previous service provider, Alexander could not believe that the relocation process could go exactly as planned, without difficulties and surprises. Anxiety was growing and he was constantly trying to speed up the process. However, the panic was not transmitted to our engineers, they acted as always: professionally, competently and with surgical precision. Therefore, in 6 hours the IT infrastructure was successfully transferred to the new data center and launched. Alexander breathed a sigh of relief and thanked us warmly for our work.
The project’s organization
Firstly, a few words about the team. Since the owner of the hardware was abroad and could not come to Germany, the project was carried out remotely. The responsibility for the result of the migration lay entirely on our company, so the team involved in this project was larger than usual. To avoid unnecessary complications with the client’s unique hardware, a specially invited engineer from IBM worked together with our certified engineers and an experienced technical specialist.
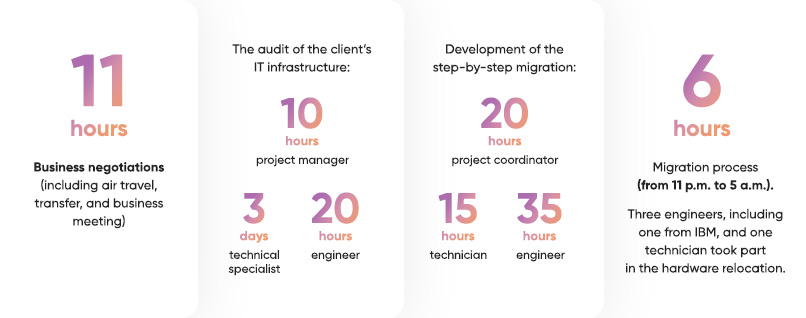
Duration and participants of each stage of the project
- Business negotiations were conducted by the project coordinator. It took around 11 working hours, including air travel, transfer, and business meeting.
- The audit of the client’s IT infrastructure involved:
- project manager (correspondence, calls, information gathering – 10 hours);
- technical specialist (visit to the old data center, preparing hardware for relocation – 30 working hours);
- engineer (visit to the old data center, inspection of the technical condition of the hardware – 20 hours);
The preparatory work was carried out over a period of three days.
3. Development of the step-by-step project of IT infrastructure migration to the new data center was carried out by:
- project coordinator (20 hours);
- engineer (35 hours);
- technical specialist (15 hours).
4. The duration of the migration was 6 hours. At 11:00 pm the hardware in the old data center was disconnected, at 05:00 am the system was already connected and working in normal mode. Three engineers, including one from IBM, and one technician took part in the hardware relocation.
Continued cooperation
The history of relations with the client did not end with the transfer of infrastructure to our data center. As it was mentioned earlier, it was important for the company to buy out the hardware and put it on the balance sheet. The client also entrusted us to solve this issue.
How we helped to buy out the hardware at residual value and put it on the company’s balance sheet
Different companies formalize hardware in different ways. Some lease resources for 3-4 years and then modernize them. Others prefer to buy it and register it as an asset, reducing costs and increasing the company’s capital. The second option was more suitable for our new client.
The owners of the enterprise had their own rationale for this approach. Perhaps they were guided by safety rules, followed corporate policy, or viewed the buyout as a way to minimize risks and business expenses. We do not know the exact reasons, but we knew the owners’ position and realized that the transfer of hardware into assets was fundamentally important to them.
Even before we met, Alexander, as the company’s representative, had signed an agreement with the previous data center for the lease of hardware necessary for the business, as well as service contracts. The conditions at that time suited the client: along with the subscription service, he paid a certain amount every month so that at the end of the contract term the residual value of the hardware would be fully paid by the company and it could be put on the balance sheet.
As we wrote above, communication with tech support was severely hampered by language barrier, and Alexander was unable to negotiate the buyout with the service provider directly. When he told us about this issue and found out that we knew very well how the buyout procedure works in Germany, he was very happy and suggested that we take care of it.
To organize the buyout of hardware is a very short phrase. But there is a large and complex block of work behind it. In particular, we had to come to an agreement with the data center where the hardware used to be located, and find buyout options satisfactory to both parties, as well as provide guarantees that the buyout would take place.
Since we already had experience in these matters, we set about solving this issue:
- negotiated and concluded a contract with the initial data center, acting as one of the parties of the deal instead of the client;
- renegotiated contracts with service companies.
In fact, CloudKleyer fulfilled the client’s obligations and bought the hardware for itself, and only then it was paid for and issued as an asset to Alexander’s company.
Contracts with the initial data center for network connections and colocation services (racks with units, Internet and IP addresses, power supply, connection of an external channel for communication, etc.) were time-limited, and it was necessary to close them correctly. We also handled the withdrawal from the contracts ourselves, so the client did not have to worry about it.
How IT infrastructure grew in the new data center
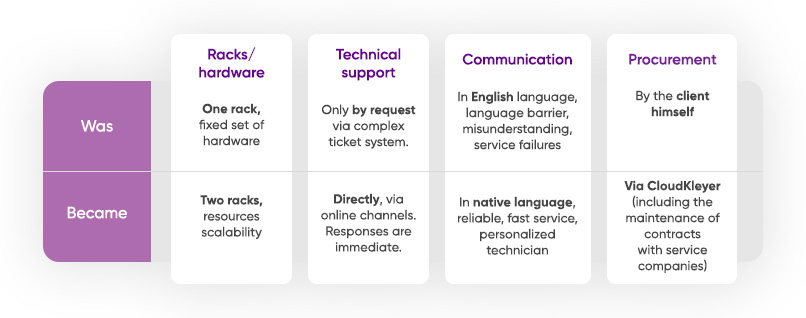
Migration to another data center opened up new prospects for the business. Previously, the client had only one rack; after moving to us, it became possible to expand the IT infrastructure. Now the company was able to rent another rack and place new resources in it:
- additional storage with extension (later an additional extension was bought to the storage);
- upgraded version of IBM Blade (Flex System X440);
- disk storage system Fujitsu Storage Eternus DX200;
Also several new servers were added in this rack.
Sometime after the relocation, at the client’s request, we migrated him to another VPN, configured on Cisco ASA 5515-X. In addition, changes were made to the IT infrastructure and additional servers and storage were purchased for them. A request was made to connect an additional ISP. Now the client receives Internet both from us and from another ISP.
These changes almost doubled the resources, and the company continues to move forward in terms of scaling. In the table below are comparative results of what was before relocation to our data center and what the client received when we started hosting their infrastructure.
Reliable service is a guarantee of IT infrastructure uptime
How to organize service for outdated models
The company we worked with on this project prefers hardware from a single manufacturer. Despite its age and peculiarities, this hardware is characterized by reliability and stability. However, because of its specificity, it requires specialized maintenance. Therefore, one of the most important points for the client was the option to receive quality technical service from a specialized company.
By signing a service agreement, we took on the responsibility of supporting these unique devices, many of which had already been removed from official service. The latter made the task difficult, but nevertheless we found companies specializing in such hardware. At first we worked with the original IBM supplier then we switched to a successor that was ready to service the old models.
Data Storage System (DSS)
As for the disks in the DSS, their condition is critical for the entire IT infrastructure. Since the client had outdated models (IBM System Storage 600Gb 3.5″ 15000RPM LFF SAS SED 49Y1983 and IBM System Storage 4Tb 3.5″ 7200 RPM 6G NL-SAS, T10 PI capable 00Y5147), the disks had to be monitored with double attention. They could fail at any time and we had to have a spare on standby. So we had to make a lot of effort to find a company producing modern analogs for the outdated hardware. It didn’t happen immediately, at first we used not quite reliable supply channels and at some point we even wanted to refuse to support storage just because of its specificity. But we were fortunate enough to find a company that supplies drives that are ideally suited for outdated hardware.
Hardware support and maintenance is our area of expertise. Failure of switches, boards, RAID controllers, drives – CloudKleyer team is ready for any technical challenges to ensure safe and reliable operation of client infrastructures, including both modern and highly outdated hardware.
Secrets of client loyalty: why they change service providers
Let’s talk about the key aspects of data center selection that many companies don’t know about or simply don’t take into account. However, they can create a lot of problems even after the IT infrastructure is migrated.
In addition to insufficient client focus, large data centers are characterized by another service-related drawback, which not only causes technical difficulties for clients, but also increases the cost of maintaining information resources.
Traditionally, big data centers have offered two models of remote technical support (remote hands):
- Standard, where it takes up to three days to process the request (the price of the service starts from €100).
- Urgent, which costs three times as much and requires a prompt decision.
However, both options involve communicating via ticket system, which causes complications, especially in case of emergencies that threaten the business with serious losses. The ticket system is designed so that without a detailed description, the technician will not start working on fixing the breakdown. And if the client has no technical skills and there is a language barrier, he or she will not be able to compose a request correctly – with all the consequences that entails.
The regulations of almost all major DCs prohibit technical specialists from responding to client inquiries by phone, email, messenger and other external channels. This is due to the fact that the ticket system fixes working time costs. At the same time, this approach greatly hampers communication, and most importantly, it delays the time to solve the actual problem, such as a server crash, disruption of network hardware, etc. As a result, the client gets into a critical situation: the IT infrastructure stops working normally and the company losses profit.
Another important point is the lack of personal responsibility for the client. Large data centers employ specialists of different levels. As a rule, they are not familiar with the peculiarities of a particular company’s IT infrastructure, because each time they send different technical specialists to fulfill a request. The client has to play a kind of lottery, the outcome of which is not always in his favor: today a competent on-call specialist came and quickly restored everything, tomorrow luck will turn away and a formalist will come who will not look into the problem.
The “history” of the client’s hardware the technician does not know. If request does not contain a detailed description of the breakdown, he will start writing to the client for clarification, looking for documents, etc. Accordingly, processing the request will take even more time, resulting in an increase of the following:
- а) service costs;
- b) IT infrastructure downtime in case of a disaster.
Both are disadvantageous to the business, and downtime is critical.
Low-quality, untimely assistance leads to significant risks for the enterprise, and the use of an inconvenient ticketing system by large data centers creates uncertainty: the client can leave a request, but it is unknown what he will get in the end. We are familiar with situations when corporate portals, web sites, and marketplaces went down only because the technician who came to the request simply turned off the hardware, considering it “unnecessary”. Reputations suffered, businesses lost money, but the data center was not responsible for this.
What conclusions can be drawn here? Placing infrastructure in a reputable DC does not guarantee that everything will work smoothly and emergency problems will be solved quickly. On the contrary, system administrators face unnecessary complications, and there is no technical protection. Having learned from the inside how work is done in large data centers, many companies are looking for an opportunity to move to a smaller data center, but with more personalized service.
It is much more convenient (and, as practice shows, more profitable) when everything is concentrated in one hands: you can lease resources and shift maintenance to the data center. There is no need to write long messages in an unfamiliar language and constantly worry that the slightest accident could lead to a disaster for the business.
Exclusive service from CloudKleyer: our benefits
Protecting the interests of the client, providing comfort and reliability – that’s what should be the priority of the service provider. At CloudKleyer we strive for these goals, so our service stands out with uniqueness and the highest level of convenience.
One-stop-shop principle + multi-lingual support + fast response time
If a client entrusts us with its IT infrastructure, we take care of all maintenance and support tasks. How it works in practice:
- We are responsible for the availability and performance of network and server hardware.
- We have complete information on each device being serviced. A technician can utilize two sources of data. First is the internal technical documentation, which is prepared for each client and contains a detailed description of the rack, hardware, serial numbers, wiring diagrams and other important information. All information is also reflected in the contract.
- We have convenient tools and interactive communication in several languages (English, German, and Spanish) to handle client inquiries.
- Each client is assigned a permanent engineer who can be contacted at any time via a convenient communication channel. The permanent engineer leads the client and deals with all current technical issues. In the absence of the primary engineer, he is replaced by another technical specialist. Having addressed the documents, he can quickly and qualitatively perform maintenance of the IT system and its individual components.
- Also, each client is assigned a personal account manager, who is the main contact person for solving all organizational and technical issues.
By entering into a service agreement with CloudKleyer, clients get another unique bonus: guaranteed replacement of failed hardware elements from the spare parts, tools and accessories (SPTA) placed on site. Continue reading to learn more.
How we ensure 99.99% SLA: monitoring, SPTA and routine hardware maintenance
Our team constantly monitors condition of client hardware hosted in the data center. If a problem is detected, such as a blinking light on one of the rack servers, we respond immediately and replace the faulty disk with a new one. We always have a spare replacement disk drive on hand for such an eventuality.
The process of monitoring and replacing disks is well-established: as a rule, clients do not even notice the work performed. They only find out about the repair when we inform them about it after it has been completed. Of course, if the replacement requires shutting down the hardware, we agree on the time in advance to minimize downtime.
Disks are one of the most critical DSS components. Considering that many companies use outdated hardware, disk replacement has become a standard service under our service contracts. We take responsibility for ensuring guaranteed availability and operability of nodes and elements of the client’s IT system. And this does not depend on whether the hardware is leased or owned, whether it is serviced by the official manufacturer or has already been removed from service.
Migration budget: how to relocate without excessive expenses
Now it’s time to summarize the results and list the benefits the company has received as a result of the relocation.
- A more favorable contract than in the previous data center. Thanks to the new conditions, the business was able to reduce the total cost of renting resources by €50,000 per year (it was €173,000, it became €123,000).
- The CloudKleyer team conducted the migration in just one night (6 hours to be precise), i.e. with minimal infrastructure downtime.
- Packing, transportation rental, hardware dismantling, unloading, loading, subsequent rack mounting, cabling, connectivity and all other related operations were carried out by us as part of the service, without any additional costs for the client.
- We helped to buy out the hardware used in the previous data center at residual value and put it on the company’s balance sheet, which reduced the company’s expenses.
This way the client was able to obtain ready assets and provide management with justification for further investments in scaling up the IT infrastructure. Due to the savings provided by the migration to our data center, the business has the prospect of expansion.
Stable tariffs for the entire term of the contract
One more important aspect of cooperation is worth mentioning. We have concluded a contract for three years with annual renewal. The cost of services has been fixed and will not change during the entire term of the contract (except for electricity prices, which do not depend on us: they are determined by suppliers and regulated by the state). Thus, the client has the opportunity to use our services practically at fixed tariffs.
If you need to relocate your IT infrastructure to a new data center, please contact us. We will be happy to help you.
The development of green technologies and environmental protection has become an integral part of business activities in Germany. Like most other businesses in the country, we emphasize environmental responsibility and strive to use technologies that do not pollute nature or harm the ecosystem. For example, to meet our energy needs, we have implemented EkoBasis, an innovative product based on the use of 100% clean energy from renewable sources. This fact is confirmed by the relevant certificate of TÜV SÜD, a reputable expert certification organization in Germany.
We use ecological innovations in the heat supply system as well. The data center generates a large amount of heat, and it is used to heat the residential buildings of an entire neighborhood. Thanks to this heat supply system, carbon dioxide emission into the atmosphere has been reduced by about 100 thousand tons, which leads to favorable consequences for the nature.
We are also actively involved in charity work. CloudKleyer is a regular partner of MainLichtblick eV. This is a non-profit charitable association that supports children with health problems and helps them realize their dreams.
By selecting CloudKleyer to migrate your IT infrastructure, you select reliability and profit! We will take care of all stages of relocation, help you relocate your hardware to a new data center without unnecessary complications and costs. Are you ready to start? Just fill out the form below:
Please contact us to get a free consultation


