Skip to main content Skip to footer
Skip to main content Skip to footer How to select server for AI. Selection of components and features of service maintenance
Contents
The rapid development of artificial intelligence is motivating commercial companies to use machine learning technologies to optimize business processes, reduce costs, and gain a competitive advantage in the market. This not only creates an increased demand for high-performance GPU servers for AI, but also directly affects the IT services market in Europe. Service providers offer various configurations of GPU servers for rent and leasing, integrate new hardware into the client’s infrastructure, and provide technical and service support.
Projects using AI technologies require the use of expensive servers with graphics chips. Depending on the set of components, AI server cost can be tens and even hundreds of thousands of euros. In these conditions, the issue of cost optimization is acute even for large companies and corporations.
One of the important advantages of cooperation with a service provider is that the client gets a machine learning server at the best price. CloudKleyer has direct contracts with the world’s leading hardware manufacturers, so it can order components at a minimum cost.
What type of server is needed to work with AI? What graphics chips are used for neural networks and machine learning? How can a service provider help with maintenance and service of AI servers? Read more about this in our article.
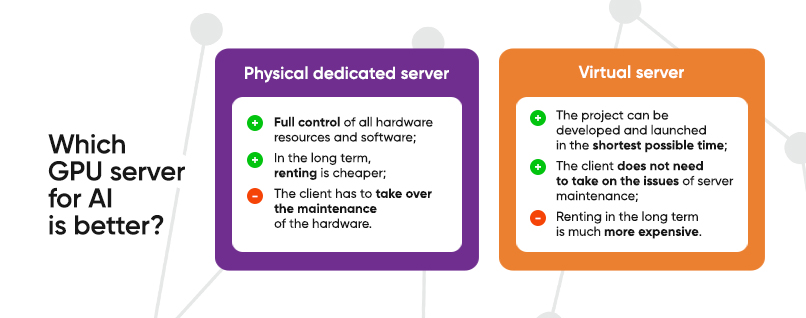
Which GPU server for AI is better, a physical or virtual one
For machine learning and logical inference tasks, you can use either a physical dedicated server for deep learning or a virtual one. Both options have pros and cons, so the choice is made depending on the technical requirements of the project.
A physical dedicated GPU server allows the client to fully control all hardware resources and software, which is a serious advantage, and sometimes a prerequisite for business. In the long term, renting or leasing a physical server is cheaper than renting a virtual machine.
The disadvantages of using a physical dedicated server for AI are reduced to the fact that the client has to take over the maintenance of the hardware: to make repairs if necessary, update the software, solve licensing issues and perform other work to ensure the operability of the hardware. Scaling the hardware resources of a physical machine is also more difficult than a virtual machine, especially in cases where this was not envisioned at the project planning stage.
The main advantages of using a virtual server are that the project can be developed and launched in the shortest possible time (3 days for development and launch), the client does not need to take on the issues of server maintenance (this work is taken on by the provider), and the performance and storage capacity of the virtual GPU server can be scaled almost infinitely.
The main disadvantage is that renting a virtual server in the long term is much more expensive than a physical server, and it is impossible to lease such a machine. For the same reason, virtual servers for AI tasks are used mainly in cases when a temporary replacement is needed or the project is not initially designed for a long period of time.
In most cases, commercial companies and organizations lease or rent physical dedicated artificial intelligence servers. At the same time, technical and service maintenance issues can always be entrusted to a service provider as part of “Remote hands” service, and at the project development stage, possible performance scaling options can be envisioned, if necessary.
Selecting components for an AI server
Machine Learning (ML) and Deep Learning (DL) models involve complex computations on very large amounts of data. For this purpose, servers are equipped with graphics chips capable of parallel computing.
As the demand for hardware for working with neural networks is constantly growing, the world’s leading manufacturers began to develop GPUs specially optimized for AI tasks. This has made the process of selecting components for servers easier, but progress moves very quickly and even the most advanced GPU models become obsolete very quickly.
To build truly optimal configurations for server AI, CloudKleyer engineers are always in touch with technical consultants of hardware manufacturers and coordinate with them the finished project. Only after that they proceed to the stage of purchasing components and assembly.
CPU for AI training server
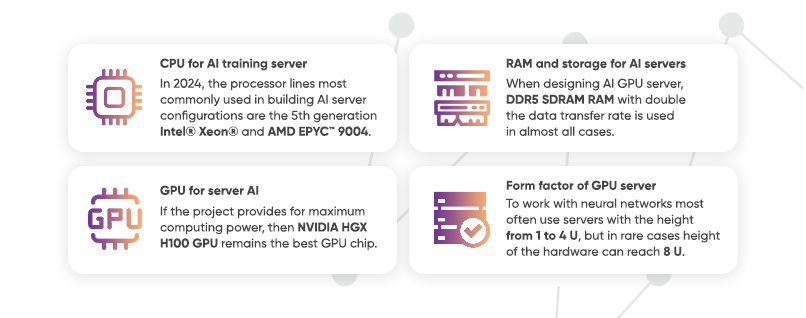
In 2024, the processor lines most commonly used in building AI server configurations are the 5th generation Intel® Xeon® and AMD EPYC™ 9004. These CPUs are great when you need high performance combined with a proven reliable ecosystem.
In some cases, earlier versions of Intel® Xeon® and AMD EPYC™ processors are used for builds. For entry-level architectures, you can consider AMD Ryzen™ series processors.
The server solution can provide both a single processor and a dual processor socket. Dual processor architectures offer higher performance, but they also have higher power consumption, so advanced cooling systems are often required.
GPU for server AI
If the project provides for maximum computing power, then NVIDIA HGX H100 GPU remains the best GPU chip in 2024. To maximize the potential of these chips, high-density modules of four or eight GPUs are integrated into liquid-cooled systems. The combination of eight NVIDIA H100 GPUs provides about 32 petaflops of deep learning FP8 performance.
NVIDIA also has a higher performance DGX H200 chip. The main difference between the H200 and H100 is a higher memory capacity of 141 GB and an increased bandwidth of 4.8 TB/S. In addition, H200 is 50% more power efficient. So far, it is the fastest AI processor in the world, but it is not yet freely available for sale.
If the client prefers AMD chips, a good alternative to H100 is GPU Instinct™ MI300X. This chip has a very large memory capacity and high bandwidth, which may be important for large language model AI. For example, famous Falcon-40 LLM, which uses forty billion parameters, can run on just one Instinct™ MI300X GPU.
If maximum computing power is not necessary, you can save money and build a server configuration with NVIDIA L4, NVIDIA L40 or NVIDIA L40S graphics chips, which were also originally optimized by the manufacturer to work with artificial intelligence.
All mentioned GPUs are well suited for both machine learning and logical inference tasks. The choice in favor of a particular solution should be made based on the business requirements for the project and financial capabilities.
RAM and storage for AI servers
When designing ai GPU server, DDR5 SDRAM RAM with double the data transfer rate is used in almost all cases. This type of memory is still the most advanced memory type available. But no matter what server configuration is designed, a single DIMM module will never be enough. Some servers are initially provided with up to 48 slots for RAM. Ultimately, the total amount of RAM depends directly on the technical requirements of the project, but industrial solutions most often require 512 to 1024 Gb RAM.
Disk drives are used in the system to permanently store information, that is, until it is automatically deleted by the user or application. In almost all cases, NVME disk drives with NVMe Gen5 interface are used for GPU server design. They have the lowest latency and the fastest data transfer rates. The total disk drive capacity also depends on business requirements, but most often two modules with 7.68 Tb each (15.36 Tb total) are sufficient.
Form factor of GPU server for deep learning
The form factor determines how much space a server will occupy in a rack. The size of servers is measured in mounting units, which are called Units or abbreviated as U. In a rack, units are always vertically positioned above each other, so the width of the server always remains standard (exception – Tower form factor), but the height will directly depend on the number of units.
To work with neural networks most often use servers with the height from 1 to 4 U, but in rare cases the height of the hardware can reach 8 U. The more CPUs and GPUs are provided by the configuration, the more powerful the cooling system should be, the more U is required to accommodate all components.
1 U high server can have up to 4 GPU slots, 4 U high server can have up to 10 GPUs. However, much depends on the type of graphics chips. There are some builds with a height of 2 U, which initially provides space for 16 single-slot GPUs. When selecting the form factor of the server, you should also remember that the cost of renting a rack will be more expensive the higher the height of the server (the number of U in the specifications).
Technical and service maintenance of GPU server for machine learning
Building and launching a GPU server is only the first stage of a business project. The overall success also depends on how stable and efficient the IT infrastructure will be. Not all client companies have qualified personnel for hardware maintenance. In this case, a service provider can help. Some additional services help to significantly reduce rental and maintenance costs.
- Service “Rent GPU server for machine learning” involves a full range of services from the provider: project development and configuration selection, purchase, connection and configuration of hardware, free unmetered Internet with a channel width of up to 100 Mb.
- CloudKleyer provides services for server migration or relocation to the provider’s data center free of charge in cases where the client intends to use “Renting server with GPU” or “Colocation” services.
- It is always possible to sign a lease contract on leasing terms. That is, the client can buy out the dedicated GPU server at the residual value after the end of the contract term. Leasing contracts are concluded for a period of 2 years or more.
- An additional agreement for maintenance can save the client from the need to solve the issues of repair, licensing of components and software, and maintenance of system operability. CloudKleyer can take care of all these responsibilities.
- Our company will also take over the free replacement of any components, even the most expensive and outdated ones, if the client pays a monthly subscription fee. The size of the regular fee directly depends on the server configuration.
When concluding a contract for GPU server rental or Colocation service, it is necessary to pay special attention to security issues. CloudKleyer is ready to offer its clients hardware hosting in a Tier 3 data center in Frankfurt am Main. Advanced ventilation and fire suppression systems are used in the data center, security service is on duty 24/7, and access to the premises of the data center is possible only by biometric data. Servers are located in cabinets with individual locks and separate power meters.
Our support team keeps in touch with clients not only by e-mail, but also in messengers. Thanks to this, even the most complex issues can be resolved as quickly as possible.
If you need a server to work with artificial intelligence, give us a call or send us a request. Our technical consultants will contact you and advise you free of charge on the main issues of project implementation and ai server price.