Relocating to a new data center in Frankfurt, building a turnkey IT infrastructure
Contents
- 1 A few words about the client: the evolution of the company and the beginning of the partnership
- 2 Selecting between relocation to a new DC and improving resilience of IT infrastructure
- 3 Benefits of distributed IT infrastructure
- 4 Project development to create a sustainable IT infrastructure with resource allocation to three DCs
- 5 Creation of a distributed IT infrastructure with high resilience: features of project implementation
- 6 Complexities and specifics of the project
- 7 Project results and client benefits
- 8 Further support and development of the client’s IT infrastructure
- 9 How to ensure the continuity of business processes with the help of a well-built IT infrastructure and a reliable service provider
Within framework of the partnership with one of our oldest clients, the oil and gas company, we had to solve various tasks: from server configuration and relocating to a new data center to remote creation of IT infrastructure on a turnkey basis. Today we will tell you how we worked on the largest project for this client, the reasons for modifying its IT structure, the difficulties encountered in the implementation process, and the benefits the company received as a result.
A few words about the client: the evolution of the company and the beginning of the partnership
The oil and gas company began its journey more than 20 years ago with a few gas stations. Over two decades, the modest business has grown into a serious holding. Now the company includes not only numerous gas stations and refueling complexes scattered all over Europe, but also cafes, restaurants, retail outlets, as well as laboratories engaged in fuel quality testing. In addition, the company is actively involved in charity, participates in social projects, pays special attention to environmental initiatives, invests in the creation of ecosystems, and supports people with disabilities.
At the initial stages of its development, the company housed its IT infrastructure in one of the data centers (DCs) located in Frankfurt am Main. All information resources consisted of EMC (formerly Dell), Cisco and HP servers, and only two racks were sufficient to house them. As long as the size of the company was relatively small, these resources were sufficient for stable operation of the enterprise. But even such a small infrastructure required high-quality service. The client could not provide support on its own, as the central office and all key departments, including the IT department, were located outside Germany. Therefore, they required a reliable partner on-site to promptly solve emerging issues. CloudKleyer became such a partner.
The cooperation started with small assignments. At first, we were engaged as remote hands to perform various operations related to maintaining the performance of hardware resources and network infrastructure in the DC: connecting, switching, creating new connections, and other specific tasks. At first, the client’s engineers personally visited the DC to evaluate our technical team and to verify the quality of service.
We proved ourselves to be reliable, and we were often entrusted with more significant and responsible tasks. And when in 2016 it became necessary to relocate racks inside the DC, the client did not hesitate to turn to our specialists.

Organizing relocation within the DC
A large-sized and non-standard EMC rack server had to be moved to a new location. To solve this task, it was necessary to perform quite a large amount of work:
- relocate the server racks to a new site inside the DC;
- dismantle, pack and ship obsolete hardware to the head office (remember, it was actually located outside of Germany, so we used a transportation company to organize the delivery);
- assist the company’s technicians in installing new hardware in the rack and set up network connections.
We usually send two specialists to fulfill typical requests. Firstly, such a team is quite enough to solve standard tasks. Secondly, there is little space around the racks: even 3-4 people simply cannot work effectively in a limited space. But for larger-scale operations, such as relocating hardware within one DC, as was the case here, or to another location, you need a bigger team. In this case, three specialists were involved, because we had to not only relocate the hardware, but also quickly connect it, which we successfully did.
Selecting between relocation to a new DC and improving resilience of IT infrastructure
Although the information system was generally stable, the centralization of hardware in one DC increased the risks. In the event of an emergency, whether it is an accident or a natural disaster, a malfunction of the DC is possible,and this will shutdown the entire infrastructure and harm the reputation of the company, which will lead to significant financial losses.
During the active development of the company and emergence of new business directions, it became obvious that the issue with limited IT resources requires an immediate solution due to the following reasons:
- Gas stations operate non-stop, 24/7, and transactions, including payment acceptance, take place around the clock. So, it is important that employees have uninterrupted access from anywhere in the world to all corporate information systems. Thus, the security and availability of IT infrastructure is a key aspect of business, because failures can seriously affect the image and financial position of the enterprise.
- Several years ago, the holding company’s management decided to digitize its business processes. Full digitalization placed higher demands on the IT infrastructure. It was necessary to develop a reliable system, resistant to failures and protected from emergencies and DDoS attacks. The task of the IT and security departments was to maximize the resilience of the infrastructure, and if the existing DC did not have enough resources for this, it was to migrate to another DC.
Benefits of distributed IT infrastructure
Experience shows that even the most reliable DCs with a high SLA of 99.99% are not 99.99% immune to loss of connectivity or power supply issues. Such incidents, even short-term, can lead to lengthy outages of client systems due to the need to fully restore operations, including checking and running databases. Ten minutes of unavailability in the DC often results in at least 3-4 hours of downtime for clients. Sometimes recovery can take a full day, especially if a third-party engineer specializing in a particular type or brand of hardware is required.
Companies that want to improve resilience and have sufficient resources often select to divide their IT infrastructure between multiple data centers in different locations. This distributed structure is primarily aimed at minimizing risks. For example, if there are power issues in one DC, it is possible to quickly switch to another DC, ensuring the continuity of business processes. If necessary, it is also possible to restore services and data from a backup copy stored in a third DC. A system physically distributed across several independent DCs is practically autonomous and immune to failures. It is very difficult to disrupt its stable operation.
There are enterprises that, when there are regular disruptions in availability, decide to simply relocate to a new DC. But this does not solve the issue globally. While distributing hardware across different locations – creating so-called “floating” resources – is a more effective solution to ensure reliability. This is why the strategy of using “floating” resources is used by leading cloud providers and large international holdings that have high demands on the resilience of their IT infrastructure. Our client has also adopted this approach as a strategy.
Project development to create a sustainable IT infrastructure with resource allocation to three DCs
We analyzed different schemes and offered the client several ways to create a resilient infrastructure. We decided on the best option: to organize the infrastructure in the form of a triangle, distributing resources across three DCs located in Frankfurt. One became the main one, the others played the role of auxiliary. All three DCs should be physically connected to each other using fiber-optic communication lines.
The design was undertaken by the holding company’s specialists. Our team was in charge of collocating client hardware in auxiliary DCs, where we had resources.
After preparing a preliminary relocation plan, engineers and technicians responsible for the project implementation internally visited our Frankfurt office to discuss the details. Also during the project development phase, they repeatedly consulted with CloudKleyer technical experts on the selection of backup lines, ways to interconnect DCs, and other technical issues.
We had a list of the hardware needed, and we calculated the purchase price. However, the company’s internal policy had its own specifics, and it turned out to be more profitable for them to purchase the hardware themselves in their home country and then deliver it to Frankfurt. Financial considerations proved to be decisive, despite the logistical inconveniences – not only did they have to select reliable transportation companies to deliver the hardware, but they also had to build a whole logistics chain.
Distributing IT resources across DCs in Frankfurt as a strategy to improve reliability
So, the client believed that relocating to a new DC would not significantly improve the resilience of the infrastructure. In his opinion, it made more sense to place IT resources in three different DCs in Frankfurt. This approach has a strong rationale:
- Frankfurt am Main leads among European cities in the number of DCs and is a key telecommunications hub (almost all major operators and providers are present here), which guarantees a high degree of network resilience.
- Ability to provide centralized service – locating the entire IT infrastructure in one city simplifies its management and support. ·
Find out which IT solution is best for your business!
Please contact us to get a free consultation
Creation of a distributed IT infrastructure with high resilience: features of project implementation
Interaction with the client
Our company has certain regulations, according to which before starting a project we always organize meetings with clients: if possible face-to-face or online via messengers Telegram, WhatsApp, or Skype. In addition, we create a working group with the participation of all key specialists involved in a particular project. This simplifies the process of interaction and allows us to promptly, in real time, resolve issues that arise.
When working on this case, we also followed a standard protocol: we held a video conference for an initial discussion of the tasks at hand, clarified the details and preferences of the client. We also requested a package of technical documents. The client’s engineers provided all the necessary diagrams and documentation, including a communications table, network connection diagram and hardware layout plans. After a thorough review of the documents, our specialists developed a project implementation plan and defined specific steps for each stage. Then the date and time of work start were approved.
Communication was done via chat, where we informed the client’s team about the completion of stages, giving the opportunity to check connections, node availability, and system operability after each operation. After receiving confirmation from the client, we moved on to the next stage. If the company’s technicians required additional time for testing or modifications, they contacted us via the same chat to agree on further actions.
Main works for creation of distributed IT infrastructure
Within the framework of the project on implementation of distributed infrastructure in two DCs our team performed a full range of works, starting from analyzing the technical schemes of installation/connection of resources provided by the client and finishing with unpacking the delivered hardware, collocating it in the rack, and launching it.
In fact, we had to implement the project on a turnkey basis. In addition to purely technical operations aimed at launching the infrastructure, we were entrusted with logistical and administrative functions.
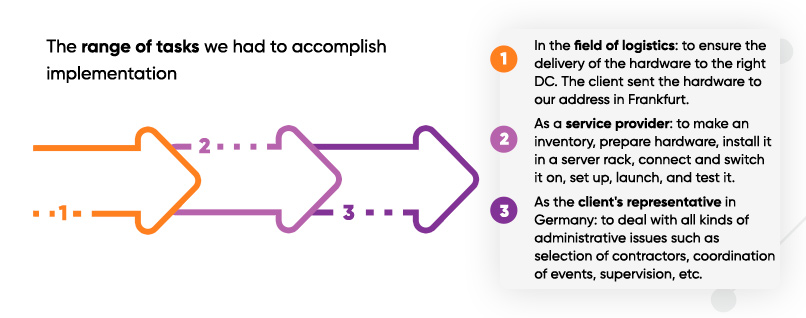
The range of tasks we had to accomplish
- In the field of logistics: to ensure the delivery of the hardware to the right DC. The client sent the hardware to our address in Frankfurt. And we had to organize transportation to the connection point, i.e. to receive the shipment from the transport company, unpack it, check its compliance, repackage it and transport it to the DC.
- As a service provider: to make an inventory, prepare hardware, install it in a server rack, connect and switch it on, set up, launch, and test it. Our specialists also had to synchronize all three DCs: first to connect them using optical lines, then to set up remote management.
- As the client’s representative in Germany: to deal with all kinds of administrative issues such as selection of contractors, coordination of events, supervision, etc.
The project involved a coordinator and three engineers from our side, and from the client’s side – four specialists from various IT departments, including the technical director. It should be added that CloudKleyer is a partner of leading hardware manufacturers: HP, Dell, Cisco, Juniper, and Huawei. Therefore, at the request of the client, we support this hardware, and in this case we also invited a dedicated expert from the vendor.
Complexities and specifics of the project
Our team already had experience in implementation of projects on migration and distribution of IT infrastructures between different DCs, one of the examples – in the case of online gambling business. So, the task set by the client was not technically difficult, but required taking into account certain features. One of the key features of the project was the idea to concentrate all resources in three DCs in Frankfurt. This case was unique, as usually the infrastructure is divided into DCs that are located close to each other, but not in the same city.
There were no serious issues during the implementation process; we encountered some minor problems when activating the communication lines. Usually the data center technical support informs us that the communication line is connected to the server rack, the port has been provided and everything can be connected by cable. But the message of readiness does not always correspond to reality: in practice, it is not uncommon for the communication line to end up inactive. The reasons can be different: from errors in the physical connection of cables in the Meet-me room to problems with connection to the server racks.
 ”According to internal regulations, DC technicians have to check and restore the serviceability of the lines. However, sometimes issues arise due to human error, such as incomplete connections or undetected damage, which leads to malfunctions. This often happens after relocating to a new data center, and not all tenants know how to deal with it. Sometimes they order a new line in the hope that it will work, i.e. they are even willing to spend extra money to avoid dealing with the data center.” – Volodymyr Marchenko
”According to internal regulations, DC technicians have to check and restore the serviceability of the lines. However, sometimes issues arise due to human error, such as incomplete connections or undetected damage, which leads to malfunctions. This often happens after relocating to a new data center, and not all tenants know how to deal with it. Sometimes they order a new line in the hope that it will work, i.e. they are even willing to spend extra money to avoid dealing with the data center.” – Volodymyr Marchenko
In our project, we also encountered this problem when, after checking, it turned out that the communication line was inactive. It was difficult for the client to solve such issues because of the distance and language barrier. We took upon ourselves to coordinate the work of technicians in two different DCs: we opened tickets in parallel and searched for the error together with them. After troubleshooting and rechecking, the problem was solved and the communication line successfully connected both DCs.
When starting data center relocation and consolidation projects, technical issues often arise during the initial setup phase. Sometimes startup failures occur despite correct server rack assembly and hardware configuring according to the client’s schematic. In such cases we provide console access to our hardware for two-way signal monitoring. We also allow the company’s engineers to configure the hardware from their side.
Project results and client benefits
Upon completion of the project, the client received a resilient IT infrastructure distributed across three DCs in Frankfurt, ensuring reliability and resource saving. Two new data centers were added to the existing one:
- our DC, which now serves as one of the key nodes;
- a backup data center – it is supposed to be used mainly for storing data backups.
The client was pleased with the result, especially with the opportunity to reduce costs by delegating functions. Creating an IT infrastructure and improving its resilience is a complex and time-consuming process that requires careful planning and coordination at every stage. It involves a whole range of activities that cannot be accomplished in two or three days:
- It is necessary to receive the hardware in the data center, unpack it and install it within a short period of time, because it cannot be stored for long in the data center. Then the devices need to be connected, plugged in and configured. These works alone take at least 2-3 weeks.
- The key to successful project implementation is effective communication with project participants, service providers and data centers, for example, at the stage of connecting communication channels and power supply. You need to find reliable contractors, negotiate and coordinate with them and the data center, invite a vendor specialist and be present at the site when he arrives. In short, be directly involved in all stages of the migration.
If the client was creating IT infrastructure in three different data centers on its own, it would require significant travel and other expenses. Our remote work allowed the company to avoid these expenses, saving time and money.
”Thanks to proper planning and professionalism of our technicians, all works were completed within a month, which is an important achievement of the project” - Olga Boujanova
Further support and development of the client’s IT infrastructure
Work on this project was the first step towards a long-term partnership with that client. After creating a distributed IT infrastructure, we not only maintain client resources, but also perform other highly sensitive tasks, including critical operations. For example, during hardware upgrade, when old servers were replaced with hardware by HP, our team was engaged in connectivity. Storage integration has a number of specifics, so under the contract with the vendor, the initial setup and launch of the system is performed by the vendor’s representative. Our tasks included coordination of actions: we conducted negotiations, participated in preparations, etc. The hardware was handed over to the holding company’s technical specialists in a fully operational state.
Remote service
After we improved resilience of the IT infrastructure, the client entrusted us with the full range of issues related to remote operations at all three Frankfurt branches. We became the main representative and contact point for all technical, logistical, organizational and administrative issues with the contractors.
In addition, we regularly install and upgrade servers, network devices, modules, other components of the IT system. On a regular basis, we are responsible for dismantling and sending obsolete hardware to the client’s office.
All new hardware, including specialized and high-valued one, is delivered to our data center, where we inventory, test and prepare it for operation. After receiving instructions from the client, we carry out the necessary distribution, connection and replacement work, regularly upgrading the infrastructure to meet growing requirements: from gigabit to 25-gigabit solutions.
Implementation of DDoS protection
In 2018, two years after the implementation of the distributed IT infrastructure, we faced a new challenge from the client’s security department: the need to implement DDoS protection for certain services.
At that time, we were already switching to new methods of preventing cyber attacks and offered the client one of our solutions: L3-level network protection, which from the company’s technical point of view was suitable. The solution successfully passed testing, including a controlled attack on the client’s sites, and was implemented.
How to ensure the continuity of business processes with the help of a well-built IT infrastructure and a reliable service provider
For a company with an extensive network of gas stations across Europe and operations in many other business areas, the reliability of information resources is crucial. The constant availability of the IT system is critical, as even a short-term interruption of communication can lead to significant financial and reputational losses. For example, if its customer is unable to pay for fuel or food due to Internet connection failure, there is an immediate impact on the business. Therefore, building a robust IT infrastructure that is resilient to disruption and cyber attacks is a priority for these large and diversified businesses.
Our company has successfully finished the task of building an IT infrastructure with high resilience, fully implementing the project with the help of its technical team.
Cooperation with the client, which started with simple remote work, has grown into a strong partnership over time. Implementation of a large project, selection of an effective DDoS solution was only a part of the work performed within the framework of the partnership. Today we provide the client with services for hardware hosting in two racks, act as a contact point in Frankfurt, and coordinate interaction with our partners: Cisco and Huawei, which are engaged in the client’s hardware maintenance.
If your company requires a resilient and well-secured IT infrastructure hosted in Frankfurt, we are ready to offer the best solution that will meet your business needs and project budget.
Ask any questions you may have at your free consulting session:
Please contact us to get a free consultation



