How to make Disaster Recovery Plan and implement effective security system for IT infrastructure of any scale
Contents
- 1 Main objectives of disaster recovery
- 2 Basic disaster recovery schemes
- 3 Preliminary risk assessment
- 4 Selection of disaster recovery solutions and requirements parameters
- 5 Disaster recovery models using cloud services
- 6 Creating Disaster Recovery Plan (DRP)
- 6.1 Step 1: Updating the contact list
- 6.2 Step 2: Creating a scheme of hardware operation and interconnection of devices in the infrastructure
- 6.3 Step 3: Identify employees responsible for the operation of hardware and services
- 6.4 Step 4: Compile a list of external contacts
- 6.5 Step 5: Approval of the final document and notification of the involved personnel
- 6.6 Step 6: Analyze and validate the backup strategy
- 7 IT infrastructure testing, service and maintenance
Disaster Recovery (DR) is a set of measures to restore IT infrastructure operation after failure of critical hardware or software problems. The fastest possible recovery of the system after a shutdown is the most important element of security, which is laid down at the stage of infrastructure development.
Recovery activities are formalized as a plan that maintenance personnel will follow in the event of a disaster. A detailed Disaster Recovery Plan (DRP) is required for businesses with sophisticated IT infrastructure. For small companies, it is enough to correctly implement a backup scheme to avoid unnecessary expenses at the maintenance stage.
CloudKleyer technical experts have extensive experience in developing disaster recovery measures. Our company provides free advice to business representatives on both security issues and IT infrastructure design. We provide backup storage equipment, hardware and software backup solutions from the world’s leading vendors Acronis and Veeam.
| Average monthly price per 500 GB | Average monthly price per 2 TB | Average monthly price per 5 TB | |
|---|---|---|---|
| Acronis | € 50 | € 150 | € 360 |
| Average monthly price per 1 GB | Average monthly price per 1 virtual machine | |
|---|---|---|
| Veeam | € 0.11 | € 11 |
Main objectives of disaster recovery
The main goal of disaster recovery activities is to eliminate data loss, minimize damage and restore hardware and services as quickly as possible. The main objectives of disaster recovery are the following:
- Designing and launching redundant systems;
- Preparation and training of service personnel;
- Preventing complete shutdown of hardware and services;
- Limiting system downtime to acceptable values or avoiding a complete shutdown in the event of a disaster;
- Minimizing the consequences of damage.
The nature and number of measures taken in each case directly depend on the scale of the IT infrastructure and the business requirements of the project.
Basic disaster recovery schemes
Disaster recovery design is always a balancing act between the likely risk of losing critical information and the level of security costs. The higher the required level of fault tolerance, the higher the technical maintenance costs.
For example, for small companies with an infrastructure consisting of a single server and a limited set of network hardware, sometimes it just doesn’t make sense to create a full-fledged disaster recovery plan. A cloud-based backup system is sufficient for them. A comprehensive approach to security is required for large companies, industrial enterprises and rapidly growing businesses.
- DRaaS Backup & Restore is a scheme for small and medium-sized companies. Does not require significant costs for creating duplicate infrastructure. You only have to pay for storing a certain amount of data in the cloud and virtual machine uptime during a disaster.
- Parallel infrastructure involves creating a complete copy of the running system. In the event of a failure of the primary infrastructure, the parallel infrastructure is started. This method requires higher operating and maintenance costs, but at the same time avoids costs and a high risk of data loss in the event of an incident.
Further we will consider in detail the scheme with parallel infrastructure construction, because only in this scheme disaster recovery plan (DRP) is an obligatory element of building an effective security system.

Preliminary risk assessment
The development of a disaster recovery package always starts with a BIA (Business Impact Analysis). This study is conducted in two stages. At the first stage, the hardware composition of the infrastructure, as well as running applications and services are determined. At the second stage, possible risks are calculated and requirements for parallel infrastructure are defined.
The main task of BIA is to prioritize all system components: hardware, software, services, and stored data. This work is done jointly by IT specialists and product managers. Each component is assigned a priority category:
- Category #1: critical importance. The first category of importance is assigned to hardware and services that must be restored as quickly as possible, as well as to data that cannot be lost even partially in the event of a disaster.
- Category #2: semi-importance. The second most important priority is given to the elements, the lack of access to which for several hours will not critically affect business processes and will not affect revenue.
- Category #3: low importance. The third category includes hardware and services, the downtime of which, measured in days, will not have a serious impact on the company’s work.
The analysis should contain reasoned assumptions about how a probable accident could affect the company’s operations. For each of the three levels, the allowable downtime is defined.
Each level should have its own SLA. This is especially important if contractors are involved in recovery processes. In hardware rental contracts, service providers always specify the allowable downtime per year. Most often it is 99% with some number of decimal places. The more decimal places after the decimal point, the higher the fault tolerance.
| SLA values | |
|---|---|
| Accessibility of services | Maximum downtime per year |
| 99 % | 3.65 days |
| 99.9 % | 8.76 hours |
| 99.95 % | 4.38 hours |
| 99.99 % | 52.56 minutes |
| 99.999 % | 5.26 minutes |
After prioritization, the levels of various threats are assessed for both the core infrastructure and the parallel infrastructure. Threats are categorized according to certain attributes.
- External threats. These include any hazards that arise from accidental or intentional human actions: cyber attacks, sabotage, criminal attacks, theft and arson.
- Insider threats. Hazards that arise from the careless or deliberate actions of employees and support staff: accidental errors, careless handling of hardware, deliberate violation of security policies, and loss of access credentials.
- Social and man-made threats. Human-caused events: civil conflicts, political unrest, epidemics, and resource depletion.
- Natural disasters. Earthquakes, tsunamis, hurricanes, floods, volcanic eruptions, any extreme weather events or conditions.
It is commonly believed that natural disasters are rarely a serious problem for infrastructure operations. In fact, the level of these threats is much higher than it may seem at first glance. The danger of natural disasters is that they also make it more difficult to deliver the resources needed to fix the accident.
Selection of disaster recovery solutions and requirements parameters
After assessing the probability of threats and risks, the next step is to define the technical requirements for disaster recovery. The technical requirements are stated using two parameters: RTO (Recovery Time Objective) and RPO (Recovery Point Objective). The cost of creating and maintaining a parallel infrastructure will directly depend on them.
- RTO is the maximum downtime of hardware or service in case of system failure. This parameter allows you to understand how much damage will be done to your business if some hardware or service is unavailable for minutes, hours or days. As an example, you take the most heavily loaded time of day and calculate the potential losses for the calculation period. If, for example, the RTO is 2 hours, then the time to restore the system should not exceed 120 minutes.
- RPO is the backup frequency. If RPO is 48 hours, then backups should be created at least once every two days.
RPO and RTO parameters are defined after SLAs for all important components of the IT infrastructure have been approved. The requirements for recovery time and backup frequency should come from the company’s managers.
The task of managers is to define RPO and RTO for all system components so that the cost of maintaining the backup infrastructure does not exceed the possible damage from data loss or service interruption in case of a disaster. It is the responsibility of the maintenance staff to ensure that the approved figures are met, taking into account the allocated budget.
The order of the approval and authorization steps may be as follows:
- Technical specialists ask management for the allowable downtime for each system component and receive a response.
- Based on the stated requirements, they determine the funding parameters and send the budget request to management for approval.
- If additional changes are required, technical requirements and budgets are jointly agreed upon.
Disaster recovery models using cloud services
There are two ways to organize a parallel infrastructure. The first is to create a full copy of the running system, and the second is to leverage cloud technologies using DRaaS (Disaster Recovery-as-a-Service).
The first approach is quite expensive and available only to corporations and industrial enterprises, while the second approach is more suitable for medium-sized businesses and large companies.
DRaaS disaster recovery scheme can be organized in three ways:
- Creation of backups and restoring data from the cloud. The simplest scheme using the Active – Passive model. Data from the main system is sent to the cloud and stored as a backup. In the event of a disaster, the time to restore from the backup will be at least an hour, so this scheme is applicable only in cases where a downtime of 60 minutes or more is not critical for business processes.
- Data replication using the Active – Standby model. This approach involves preparing virtual machines that are constantly in standby mode. The RTO value in this case may not exceed 30 minutes, and RPO – 15 minutes. The data replication model is optimal for companies working in e-commerce and BigData.
- Data replication using the Active – Active model. A scheme is organized according to the mirror principle. Data from the main system is synchronously transferred to the duplicate system, which runs in the cloud and works in parallel with the main system. RTO with this approach rarely exceeds 30 seconds, and RPO is equal to zero. The Active – Active model is used by banks, financial organizations and companies for which a system shutdown of more than 30 seconds is critical to business processes.
CloudKleyer service provider offers its clients to select any scheme and model of recovery systems. To organize backup, we use turnkey software solutions from the world’s leading manufacturers: Acronis and Veeam. For data storage our clients can select both dedicated servers and virtual machines. The configuration of hardware is selected for the project individually in each case. We provide consultations free of charge.
Creating Disaster Recovery Plan (DRP)
Once the key disaster recovery requirements have been established, a software solution has been selected and a budget has been agreed upon, it’s time to develop a disaster recovery plan (DRP).
The first step in creating this document is an inventory. Lists of working hardware, software, services and employees involved in IT infrastructure maintenance are compiled.
During long-term operation of the system, errors and undocumented settings accumulate, and there may be difficulties in organizing the access level. These issues may not be apparent until an incident occurs. Preparing a formal document with a DRP plan helps to understand the situation here and now.
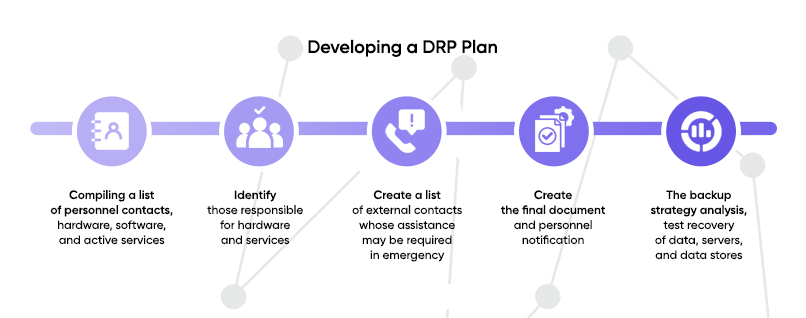
The whole process of developing a plan can be divided into several successive stages.
Step 1: Updating the contact list
The first step is to determine the list of employees who will be involved in the system recovery efforts if a disaster occurs. Then the contacts of each of them are entered into the document. If the contact list already exists, the data is updated, if not, a new one is created. Each employee is asked not only for personal contacts, but also for contacts of their friends or close relatives.
Step 2: Creating a scheme of hardware operation and interconnection of devices in the infrastructure
After the contacts list is created, a scheme of the system’s operation is drawn up, all active elements are taken into account, including network and peripheral devices, the workload of electronic communications is assessed, and the amount of resources required for the operation of each service is recorded.
Step 3: Identify employees responsible for the operation of hardware and services
At this stage, the roles and levels of responsibility of each involved employee are defined.
- Deputies are appointed in case of absence of managers.
- Each employee’s level of professional compliance is checked. If difficulties arise, additional training is provided.
- All service personnel are required to double-check access levels and the relevance of logins and passwords.
- A document with the distribution of roles and responsibilities is drawn up. The list of contacts of key employees is duplicated in it to reduce the time needed to find them at the time of an accident.
Step 4: Compile a list of external contacts
The fourth step is to compile a list of partners and counterparties whose assistance or services may be needed during disaster recovery. This list should include contacts of service providers, hardware and software vendors, communication channels to support critical services, and phone numbers of emergency services.
A separate list includes communication channels with utilities. This data is required in case of serious infrastructure failures.
Step 5: Approval of the final document and notification of the involved personnel
Next, make the necessary number of copies of the final document with the procedure and nature of actions in the event of an incident. At least one paper copy is stored in a safe place, for example, in a safe or a document archive. Electronic copies of the document are sent to all employees involved in disaster recovery activities by e-mail.
Step 6: Analyze and validate the backup strategy
The final step is to verify that the backup scheme meets the required security conditions. Once the disaster recovery plan is established and approved, test recovery of data, servers and storage systems is performed. It is important to set up a proper notification system in case the backup system fails.
IT infrastructure testing, service and maintenance
It is never enough to prepare a disaster recovery plan and perform unit tests. The system is constantly undergoing changes, software updates are being installed, new components and services are being introduced, and warranty periods for old hardware are expiring.
Service personnel responsible for restoring the infrastructure in the event of a disaster must constantly train. To this end, a schedule of inspections is established and a variety of situations are considered: cyber attacks, loss of access, server crashes, power outages and other possible incidents.
There are many options for organizing parallel infrastructure operation and creating reliable backup mechanisms. If you need help in designing backup systems or require backup storage capacity, contact us. We will suggest the best solutions and advise you on hardware selection completely free of charge.



